K-Flow 的物理起源
(★ 这篇文章是刘圣超老师的邀稿, 请参考他们实验室的主页 Wave Intelligence Lab ★)
从物理视角看流匹配
花粉在水中的随机运动,即布朗运动,是人类最早在自然现象中观察到的随机性现象之一。作为一种肉眼可见的微观扰动,这一现象启发了人们从大量微观粒子的随机运动出发,对气体行为作出微观解释。扩散作为自然界中普遍存在的基本输运过程之一,随后受到了物理学家和数学家的广泛关注与深入研究。相关理论逐渐发展为描述粒子、能量以及概率分布随时间演化的重要基础,并进一步为现代输运理论以及机器学习中的生成式扩散模型奠定了关键的理论基础。流匹配作为当前最先进的生成式建模框架之一,也可以从物理学的视角加以诠释。其数学结构与经典力学中的输运动力学高度相关,尤其体现在概率密度在给定速度场作用下的演化过程上。这使得流匹配不仅是一种强大的机器学习方法,也能够借助既有的物理图景获得更深层次的理解与解释。流匹配的动力学由以下常微分方程定义:
\[\dot{x}_t = v_t(x_t),\]其中,$v_t(x)$ 表示在数据空间上定义的、随时间变化的速度场。与显式建模随机性的生成范式不同,流匹配刻画的是一种由 $v_t$ 所诱导的确定性动力学演化过程,其对应的状态轨迹也因此是确定的。概率密度在该流场下的演化必须满足如下连续性方程:
\[\partial_t p_t(x) + \nabla \cdot \bigl(p_t(x)\, v_t(x)\bigr) = 0,\]其中,$p_t(x)$ 表示时刻 $t$ 的边际分布。该方程本质上是总概率守恒的直接体现:尽管概率密度在演化过程中可能会随着速度场 $v_t$ 在局部发生扩张或收缩,但整体概率始终保持守恒。进一步地,沿着一条特征轨迹 $x_t$ 演化时,有
\[\frac{\mathrm{d}}{\mathrm{d}t} p_t(x_t) = -\, p_t(x_t)\, \nabla \cdot v_t(x_t).\]这表明,概率密度沿轨迹的变化率由速度场在该点的散度所决定。当 $\nabla \cdot v_t(x_t) > 0$ 时,概率流发生扩张,对应的概率密度下降;当 $\nabla \cdot v_t(x_t) < 0$ 时,则情况相反。从这一角度看,流匹配可以被理解为学习一个概率分布如何通过连续输运演化为另一个分布的过程。这样的物理图景在物理学中十分常见。类似的连续性结构也广泛出现在电动力学、流体力学和量子力学中,即在研究某种守恒量随时间演化时都会自然出现。一个典型而清晰的例子是哈密顿力学。在哈密顿系统中,相空间中的输运动力学由辛向量场决定,其诱导的流场保持相空间体积不变,因此散度为零:
\[\nabla \cdot v_t = 0 \quad \Longrightarrow \quad \frac{\mathrm{d}}{\mathrm{d}t} p_t(x_t)=0.\]这意味着沿着系统的特征轨迹演化时概率密度保持不变。哈密顿方程组写作
\[\dot q = \frac{\partial H}{\partial p}, \qquad \dot p = -\frac{\partial H}{\partial q},\]其中,$q$ 和 $p$ 分别表示广义坐标与共轭动量。在哈密顿力学中,系统的运动可以表示为其在由 $(q,p)$ 参数化的相空间中的轨迹。为了刻画系统状态在相空间中的分布,可以自然地引入相密度 $\rho(q,p,t)$ 这一概念。由于系统状态数守恒,相密度的演化满足如下连续性方程:
\[\frac{\partial}{\partial t}\rho(q, p, t) + \nabla \cdot (\rho v) = 0,\]其中,相速度定义为
\[v = (\dot q, \dot p).\]这一速度场的散度为
\[\nabla \cdot v = \frac{\partial \dot q}{\partial q} + \frac{\partial \dot p}{\partial p} = \frac{\partial^2 H}{\partial q\, \partial p} - \frac{\partial^2 H}{\partial p\, \partial q} = 0.\]因此,哈密顿流保持相空间体积不变,这正是刘维尔定理在经典力学中的一种常见表述。与之等价地说,相密度沿系统轨迹保持常数,即
\[\frac{\mathrm{d}}{\mathrm{d}t}\rho(q, p, t) = 0.\]这也为理解流匹配提供了一个自然的物理视角。与哈密顿输运类似,流匹配同样描述了密度在向量场作用下的演化过程。二者的关键区别在于,流匹配并不要求相空间体积守恒;它所学习的是一种允许局部收缩或扩张的概率流,从而将一个概率分布连续地输运为另一个概率分布。从这个意义上说,流匹配可以被看作一种广义的输运过程:它放松了经典力学中的不可压缩性约束,同时保留了相似的连续性结构。
尺度的演化: 从重整化群到K-Flow
在传统的流匹配框架中,时间参数 $t$ 有时显得并不十分自然。由于概率流不再保持体积守恒,时间也就无法像上述物理图景中那样,作为一个自然的对称参数被直接引出。这便引出了一个值得思考的问题:我们是否可以不再用时间来刻画系统的演化,而改用尺度这一变量?在凝聚态物理和量子场论中,这一问题最终导向了重整化群的思想。其核心出发点在于,自然界中的统计系统往往在不同的长度尺度或能量尺度上表现出某种自相似性。因此,我们自然需要一种理论框架,用以描述有效理论中的参数如何随着尺度的变化而演化。在重整化群理论中,耦合参数 $g$ 随系统有效能量尺度 $k$ 的演化由重整化群方程决定:
\[\frac{\partial g}{\partial \ln k} = \beta(g),\]其中,$\beta(g)$ 是刻画有效理论随尺度变化而演化的 Beta 函数。这个方程所描述的不再是系统随时间的演化,而是其随尺度变化的过程。
这一视角也自然启发了我们对生成式流匹配的重新理解:与其引入一个较为抽象的时间参数,不如采用一个具有明确物理意义的尺度参数来刻画演化过程。一个有趣且重要的观察是,在许多物理系统中,类能量参数往往与频率或波数的平方成正比。例如,在量子力学中,我们经常会遇到如下形式的关系:
\[E \propto k^2.\]对于自然图像或其他具有结构性的信号,类似的尺度信息可以通过$K$-变换提取,例如傅里叶变换或小波变换。记 $\phi_k$ 为尺度 $k$ 上的变换系数,则其强度可以自然地与一个随尺度变化的“能量”联系起来:
\[E_k \propto \|\phi_k\|^2.\]这为组织不同尺度上的信息提供了一种具有明确物理动机的方式,而不必人为引入一个抽象的时间参数。在这一视角下,K-Flow 的动力学方程可以写为
\[\frac{\mathrm{d}\Psi_k}{\mathrm{d}k} = v_k(\Psi_k),\]其中,$\Psi_k$ 表示随尺度 $k$ 变化的可观测量,$v_k$ 则是由尺度所诱导的速度场。
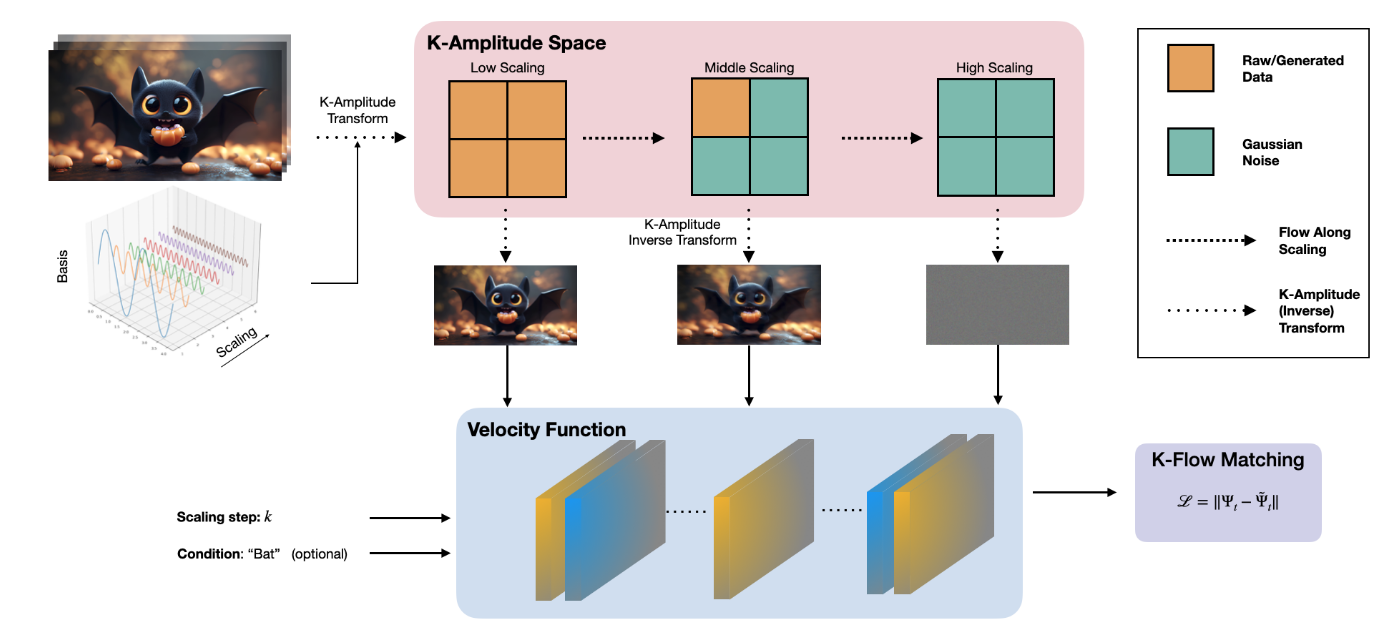
更准确地说,$\Psi_k$ 是通过如下方式构造的一个中间量,用于描述输运动力学:随着尺度 $k$ 的增大,逐步显露更大尺度上的变换系数,而其余尚未显露的系数则以噪声填充。其具体定义为
\[\Psi_k = \mathcal{F}^{-1} \Big( \mathbf{1}_{\sqrt{k_x^2+k_y^2+k_z^2}<\lfloor k \rfloor}\,\mathcal{F}\{\phi\} + \bigl(1-\mathbf{1}_{\sqrt{k_x^2+k_y^2+k_z^2}\ge \lfloor k \rfloor + 1}\bigr)\epsilon + \mathbf{1}_{\sqrt{k_x^2+k_y^2+k_z^2}\in[\lfloor k \rfloor,\lfloor k \rfloor+1)} \bigl( \mu(t)\,\mathcal{F}\{\phi\} + (1-\mu(t))\,\epsilon \bigr) \Big),\]其中,$\mathbf{1}$ 表示示性函数,$\mathcal{F}$ 表示 $K$-变换,$\epsilon$ 为高斯噪声,$t = k-\lfloor k \rfloor$ 则表示在某一尺度球壳内部的演化参数。这一构造提示了它与重整化群之间的紧密类比:
\[\frac{\mathrm{d}\Psi_k}{\mathrm{d}k} = v_k(\Psi_k) \qquad \Longleftrightarrow \qquad \frac{\partial g}{\partial \ln k} = \beta(g).\]在这两种情形中,核心对象的演化都不是沿着物理时间展开的,而是沿着一个用来组织系统自由度的尺度参数展开。从这一视角来看,K-Flow 可以被理解为一种沿尺度进行的输运过程,其中信息在不同频率带之间被逐步生成或重建。
当然,这一类比在严格的场论意义下并不是完全精确的,但它在概念上是很有启发性的:重整化群描述的是有效理论如何随着尺度变化,而 K-Flow 描述的则是可观测量如何在变换空间的尺度层级之间被连续输运。
这种沿尺度展开的结构还导向了一种局域化的概率解释。由条件概率的 telescoping decomposition,我们有
\[p_t(\cdot) = p(k_0)\cdots p_t(\cdot\mid \lfloor k \rfloor,\ldots,k_0)\, p_{\epsilon}(\lfloor k \rfloor+1)\cdots p_{\epsilon}(k_{\max}\mid k_{\max}-1,\ldots,k_0),\]因此,第 $t$ 步对应的边际分布实际上在当前的尺度球壳附近是局域化的。换句话说,真正被主动更新的只有一个受限的系数带:较低尺度上的分量已经基本确定,而较高尺度上的分量仍然主要由噪声主导。
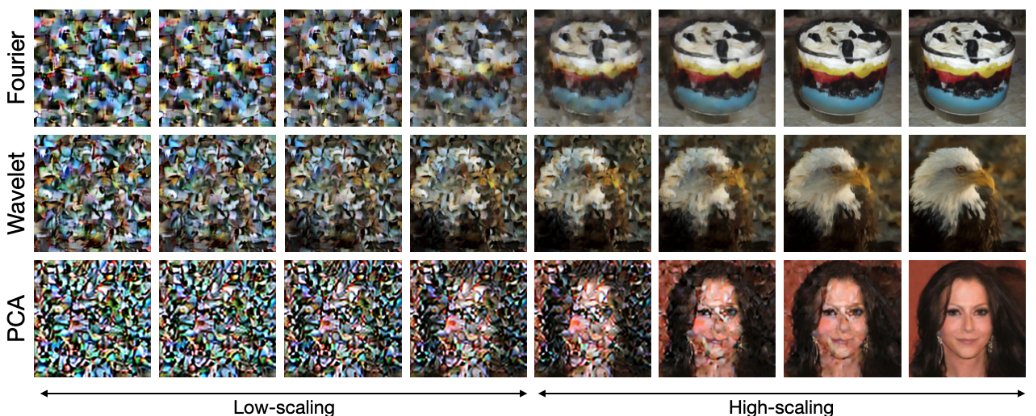
这与重整化群理论中的壳层局域化概念十分相似:在那里,我们关心的是当系统的自由度按壳层逐步积掉或引入时,有效描述如何发生变化。从这个角度看,K-Flow 用一种更有结构、也更容易获得物理诠释的尺度演化,替代了传统流匹配中较为抽象的时间变量。
K-Flow的实验表现
在 K-Flow 论文中,我们在多种数据集上进行了广泛实验,既包括 条件生成 ,例如带有 VAE 的 ImageNet-256,也包括 无条件生成,例如 CelebA-HQ。
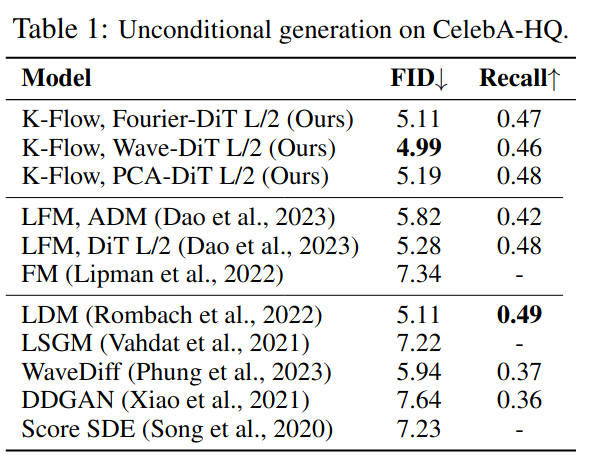
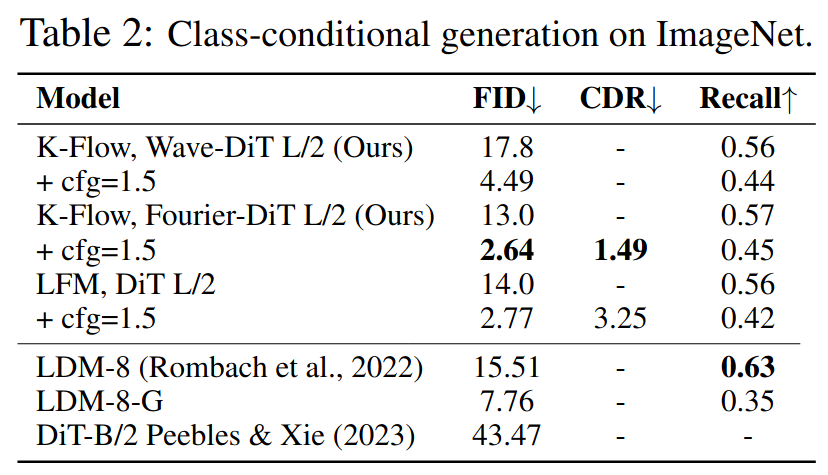
在这些基准任务上,K-Flow 取得了具有竞争力的结果,如 Table 1 和 Table 2 所总结的那样。更有趣的是,我们观察到一个十分显著的现象:在生成过程的很早阶段去除 分类标签,并不会明显降低生成样本的质量,如下图所示。

这一结果为我们的 能量驱动方法 提供了有力的实验支持:它所学习到的内部表征,与 自然图像流形 具有高度一致性,而并非仅仅在整个生成过程中持续依赖标签信息。
总结与展望
尽管我们的框架不仅在理论上具有启发性,也在实践中展现出了良好的效果,但当前的方法仍然在很大程度上受限于 VAE 所诱导的潜空间。这一限制使得模型尚无法直接在像素空间中学习显式表征。无论是从理论还是应用的角度来看,仍然存在若干值得进一步探索的方向:
-
将 K-Flow 推广到潜空间生成之外。 我们能否借助更高效的模型架构,使 K-Flow 直接在像素空间中进行训练?更进一步地,K-Flow 的形式是否可以被推广到 参数高效微调(PEFT) 的设定中,从而提升现有预训练模型的使用效率?
-
将 K-Flow 应用于科学生成任务。 我们能否将 K-Flow 框架应用到那些存在真正可解释能量泛函的科学领域中?这类问题或许能够为 K-Flow 的理论基础提供一个更加直接且严格的检验场景。
我们相信,这些问题为未来的研究打开了许多令人期待的方向。
如果你认为这项工作对你有所启发或帮助,欢迎引用我们的论文!
@misc{du2025flowkamplitudegenerativemodeling,
title={Flow Along the K-Amplitude for Generative Modeling},
author={Weitao Du and Shuning Chang and Jiasheng Tang and Yu Rong and Fan Wang and Shengchao Liu},
year={2025},
eprint={2504.19353},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2504.19353},
}